HSR Detection
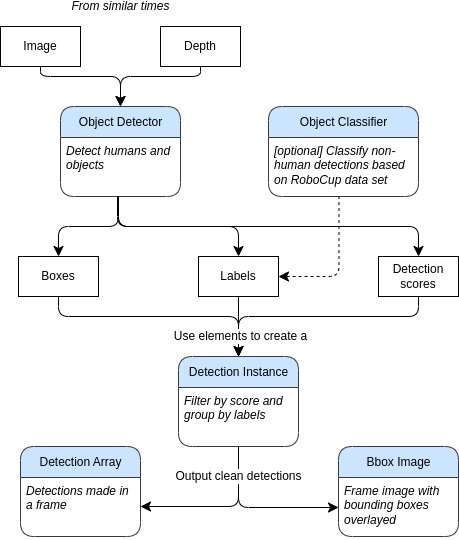
Object Detection allows the robot to use the visual and depth input from its RGB-D cameras to determine the identity and location of objects in the surroundings. With reference to the above image, the current image from the camera being inputted into the model, which in turn outputs a bounding box for an object, the object’s identity, and the confidence level. We then process the output by applying non-maximum suppression to the set of outputs to remove duplicate detections, then apply a minimum confidence threshold. Image coordinates of detected objects are transformed into 3D using ROS tf. Currently, Team ORIon-UTBMan have implemented a Faster R-CNN model with a ResNet-50-FPN backbone, which have been pre-trained on the COCO datasets. Click on the button below to see a video demonstration.